Abstract
We have recently seen tremendous progress in realistic text-to-motion generation. Yet, the existing methods often fail or produce implausible motions with unseen text inputs, which limits the applications.
In this paper, we present OMG, a novel framework, which enables compelling motion generation from zero-shot open-vocabulary text prompts. Our key idea is to carefully tailor the pretrain-then-finetune paradigm into the text-to-motion generation.
At the pre-training stage, our model improves the generation ability by learning the rich out-of-domain inherent motion traits. To this end, we scale up a large unconditional diffusion model up to 1B parameters, so as to utilize the massive unlabeled motion data up to over 20M motion instances.
At the subsequent fine-tuning stage, we introduce motion ControlNet, which incorporates text prompts as conditioning information, through a trainable copy of the pre-trained model and the proposed novel Mixture-of-Controllers (MoC) block. MoC block adaptively recognizes various ranges of the sub-motions with a cross-attention mechanism and processes them separately with the text-token-specific experts. Such a design effectively aligns the CLIP token embeddings of text prompts to various ranges of compact and expressive motion features.
Extensive experiments demonstrate that our OMG achieves significant improvements over the state-of-the-art methods on zero-shot text-to-motion generation.
Video
Methods
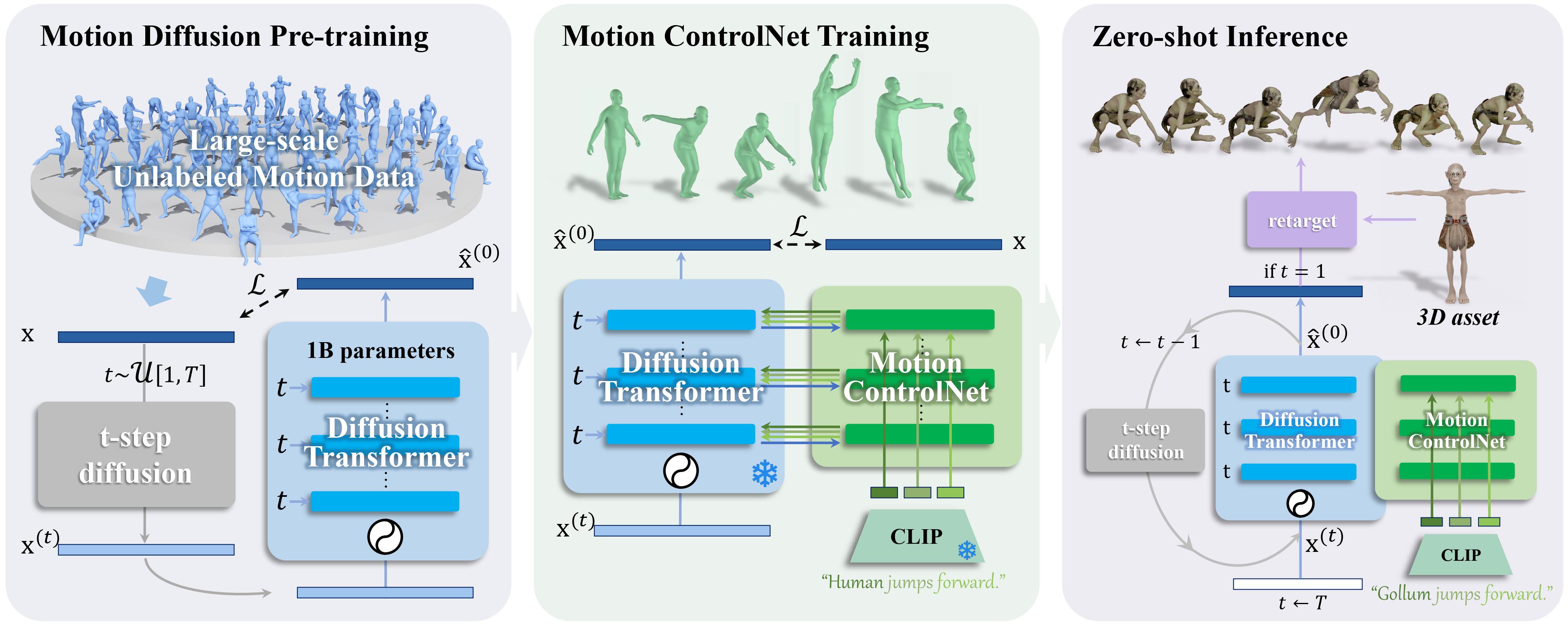
We train our OMG model in two stages. First, we leverage large-scale unlabeled motion data to pretrain an unconditional diffusion model with up to 1B parameters. Then, we adopt a conditional fine-tuning scheme called motion ControlNet to condition the pre-trained diffusion model on text prompts. During inference, the pre-trained unconditional denoiser and the fine-tuned conditional denoiser are combined with classifier-free guidance, generating realistic motions with zero-shot text inputs.
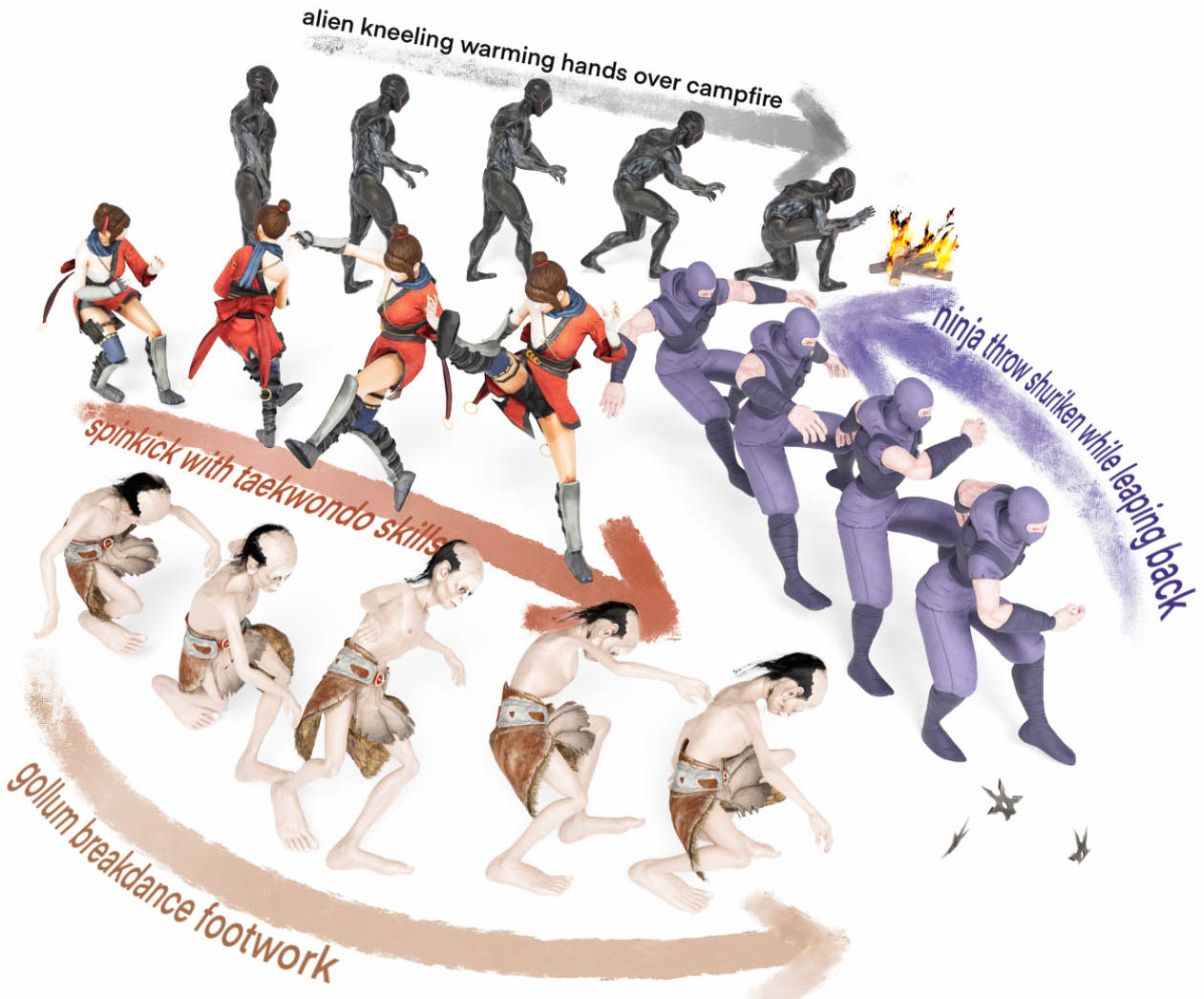
Qualitative results
We show qualitative results generated by our model given various text prompts. Our model effectively captures the motion characteristics from either a single phrase or longer natural sentences.
More results
BibTeX
@inproceedings{liang2024omg,
title={Omg: Towards open-vocabulary motion generation via mixture of controllers},
author={Liang, Han and Bao, Jiacheng and Zhang, Ruichi and Ren, Sihan and Xu, Yuecheng and Yang, Sibei and Chen, Xin and Yu, Jingyi and Xu, Lan},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={482--493},
year={2024}
}